InternLM-XComposer2-4KHD: A Pioneering Large Vision-Language Model Handling Resolutions from 336 Pixels to 4K HD
公和众和号:EDPJ(进 Q 交流群:922230617 或加 VX:CV_EDPJ 进 V 交流群)

目录
0. 摘要
3. 方法
3.1 模型架构
3.2 高分辨率输入
3.3 预训练
3.4 4KHD 监督微调
4. 实验
0. 摘要
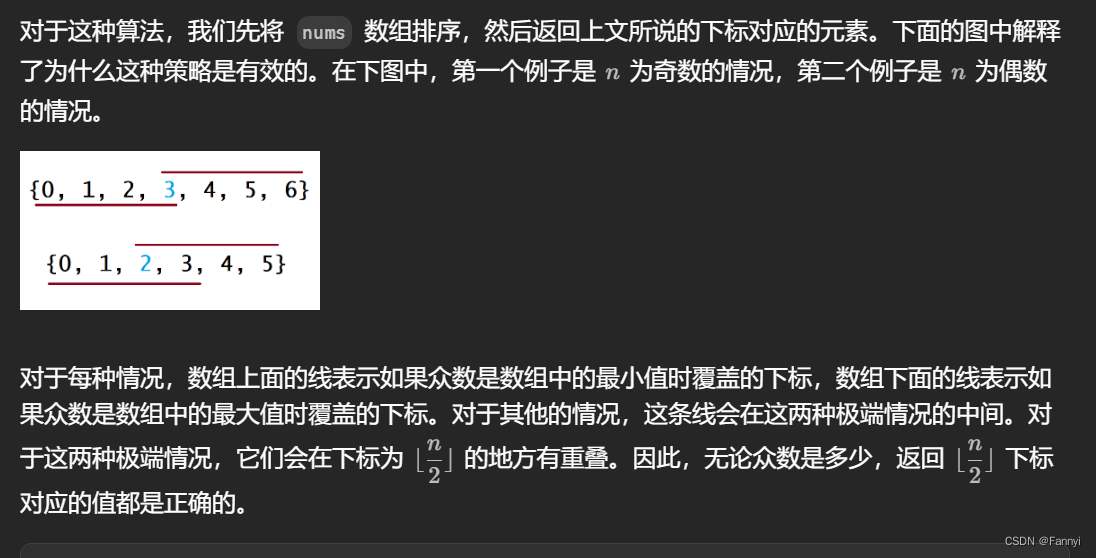
大型视觉-语言模型(Large Vision-Language Model,LVLM)领域取得了显著的进展,但由于分辨率有限,对细粒度视觉内容的理解受到了挑战。最近的努力旨在提高 LVLM 的高分辨率理解能力,但它们仍然受到了约 1500×1500 像素的限制,并且受到了相对狭窄的分辨率范围的限制。本文介绍了 InternLMXComposer2-4KHD,这是对提高 LVLM 分辨率能力的突破性探索,将 LVLM 分辨率能力提升到 4K HD(3840×1600)甚至更高。与此同时,考虑到超高分辨率可能并非在所有场景中都是必要的,它支持从 336 像素到 4K 标准的广泛分辨率范围,显著扩大了其适用范围。具体来说,本研究通过引入一种新的扩展来推进补丁划分范式:动态分辨率与自动补丁配置。它保持了训练图像的宽高比,同时根据预训练的 ViT(336×336)自动变化补丁数量并配置布局,从而实现了从 336 像素到 4K 标准的动态训练分辨率。我们的研究表明,将训练分辨率扩展到 4K HD 可以持续提升性能,而不会达到改进的上限。InternLM-XComposer2-4KHD 在 16 项基准测试中表现出出色的能力,在其中 10 项中与甚至超过了 GPT-4V 和 Gemini Pro。
项目页面:https://github.com/InternLM/InternLM-XComposer



3. 方法
3.1 模型架构
InternLM-XComposer2-4KHD 的模型架构主要遵循 InternLM-XComposer2 的设计(以下简称为 XComposer2),包括一个轻量级的视觉编码器 OpenAI ViT-Large/14、大型语言模型 InternLM2-7B 和 Partial LoRA 用于有效的对齐。我们建议读者参考 XComposer2 论文以获取更多细节。
(2024,MLLM,视觉语言模型,用于模态对齐的部分 LoRA)InternLM-XComposer2

3.2 高分辨率输入
动态图像分割(Dynamic Image Partition)。对于处理高分辨率图像,特别是具有不同宽高比的图像,将静态输入图像大小视为固定不变的方法既不高效也不有效。为了克服这一限制,我们引入了一种动态图像分割方法,如图 4 所示。我们的方法在保持原始图像宽高比完整性的同时,策略性地将图像分割成较小的补丁(patch)。
给定最大分割数 H,尺寸为 [h,w] 的图像 x 被调整大小并填充到尺寸为 [ph × 336, pw × 336] 的新图像 ˆx。此过程受以下约束条件的限制:
![]()
这里的 pw 和 ph 分别表示每行和每列的补丁数。然后我们将 ˆx 分成 ph × pw 个不重叠的补丁。每个补丁是一个尺寸为 336×336 的小图像,我们将这些补丁视为 ViT 的单独输入。 接下来,我们使用 'HD-H' 表示具有 H 补丁约束的高分辨率设置。例如,'HD-9' 允许最多 9 个补丁,包括一系列分辨率,如 1008×1008、672×1344、336×3024 等。
全局-局部格式。对于每个输入图像,我们向模型展示两种视图。第一种是全局视图,在此视图中,图像被调整为固定大小(在我们的情况下为 336×336)。这提供了对图像的宏观理解。根据经验,我们发现这对于 LVLM 正确理解图像至关重要。第二种视图是局部视图。我们使用先前提到的动态图像分割策略将图像分割成补丁,并从每个补丁中提取特征。在特征提取后,将这些补丁重新组合成一个大的特征图。然后,在一个简单的 token 合并过程后,对特征图进行扁平化处理,得到最终的局部特征。
图像 2D 结构换行指示符。鉴于图像具有 2D 结构且图像比例是动态的,每行的标记数可能在不同图像之间变化。这种变化可能会让 LVLM 感到困惑,使其难以确定哪些标记属于图像的同一行,哪些属于下一行。这种混淆可能会妨碍 LVLM 理解图像的 2D 结构,而这对于理解文档、图表和表格等结构化图像内容至关重要。为了解决这个问题,我们在扁平化之前在每行图像特征的末尾引入了一个可学习的换行('\n')标记。最后,我们将全局和局部视图连接起来,在它们之间插入一个特殊的 'separate' 标记以区分这两种视图。

3.3 预训练
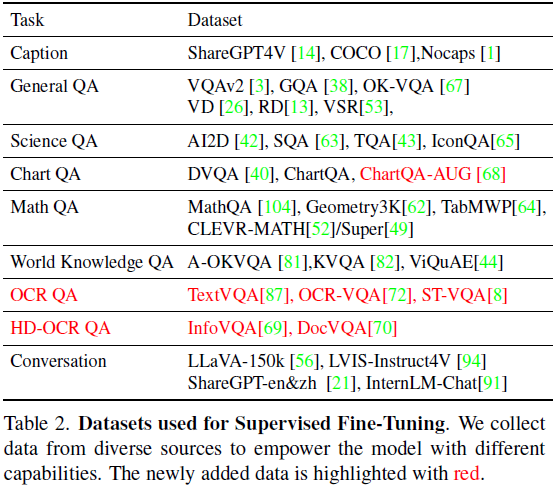
在预训练阶段,LLM 被冻结,而视觉编码器和 Partial LoRA 被微调以将视觉 token 与 LLM 对齐。预训练数据主要遵循 XComposer2 中的设计,考虑了三个目标:1)一般语义对齐,2)世界知识对齐,3)视觉能力增强。在本文中,我们专注于高分辨率和结构化图像理解。因此,我们收集了更多相关数据以增强这一特定能力。如表 1 所示,我们利用了一个多样的 OCR 数据集来实现这个目标。
在实践中,我们使用 OpenAI CLIP ViT-L-14-336 作为视觉编码器。与 XComposer2 不同,我们保持 ViT 的分辨率为 336×336,并增加输入分辨率以增加更多的补丁。对于动态图像分割策略,我们使用 'HD-25'。对于每个图像或补丁,通过简单的合并操作将图像 token 数量减少到原来的 1/4。我们将附近的 4 个 token 通过通道维度合并成一个新的 token,然后通过 MLP 将其与 LLM 对齐。'separate' 和 '\n' 标记是随机初始化的。对于 Partial LoRA,我们为 LLRM 解码器块中的所有线性层设置了秩为 256。我们的训练过程使用 batch 大小为 4096,并跨越 2 个 epochs。学习率在前 1% 的训练步骤中线性增加到 2 × 10^(-4)。在此之后,根据余弦衰减策略将其减少到 0。为了保留视觉编码器的预先存在的知识,我们应用了一种逐层学习率(layer-wise learning rate,LLDR)衰减策略,衰减因子设置为 0.90。
3.4 4KHD 监督微调
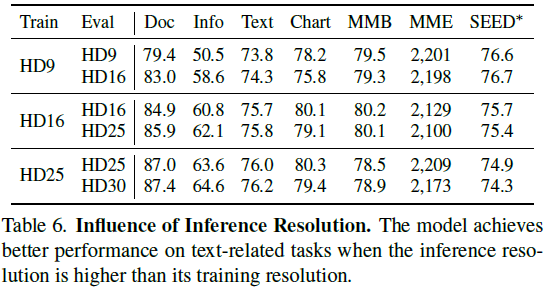
在预训练之后,我们增强模型的理解高分辨率图像和解决各种挑战。与先前的感知任务(例如 VQAv2、GQA)不同,这些任务通常根据图像中显著的对象来回答问题。OCR 相关任务依赖于对高分辨率图像中文本的详细理解。例如,在 InfoVQA 中,50% 的图像中较长边的长度超过了 2000 像素。低分辨率的输入可能会扭曲密集的文本信息,导致模型在理解上失败。然而,我们观察到了上述感知任务中的分辨率饱和问题,其中分辨率的影响变得可以忽略不计。
为了解决这个问题,我们引入了一种混合分辨率训练策略以实现更高效的训练。对于需要高分辨率的任务,在训练期间我们使用 'HD-55' 设置。这允许输入 4K(3840×1600)图像而不需要额外的图像压缩。这些任务在表 2 中被称为 HD-OCR QA 任务。对于其他任务,我们实现了动态分辨率策略。图像被调整大小以在其原始大小和由 'HD25' 设置指定的大小之间。这种动态方法增强了 LVLM 对输入分辨率差异的稳健性,从而使 LVLM 在推理期间能够利用更大的分辨率。例如,当 LVLM 在 'HD25' 设置下训练时,我们观察到使用 'HD30' 设置在大多数 OCR 相关任务上产生更好的结果。
在实践中,我们联合训练所有组件,batch 大小为 2048,跨越 3500 个步骤。我们以加权的方式对来自多个来源的数据进行抽样,权重基于每个来源的数据量。由于 'HD-55' 具有 'HD-25' 的双倍的图像 token 数量,我们调整了数据加载器以为它们启用不同的 batch 大小,并相应地调整它们的权重。最大学习率设置为 5×10^-5,并且每个组件都有自己独特的学习策略。对于视觉编码器,我们将 LLDR 设置为 0.9,这与预训练策略一致。对于 LLM,我们采用固定的学习率缩放因子为 0.2。这会减缓 LLM 的更新速度,实现保留其原始能力和与视觉知识对齐之间的平衡。
4. 实验